Regaining Speech: Implementing Neuroprosthetic Solutions
(Posted on Monday, March 4, 2024)

This article was originally published on Forbes on 3/4/24.
This story is part of a series on the current progression in Regenerative Medicine. This piece discusses advances in neuroprosthetic technology.
In 1999, I defined regenerative medicine as the collection of interventions that restore normal function to tissues and organs damaged by disease, injured by trauma, or worn by time. I include a full spectrum of chemical, gene, and protein-based medicines, cell-based therapies, and biomechanical interventions that achieve that goal.
A new device has been developed that allows you to speak by thought alone, without the vocal cords. This is useful for people with neurological damage who can no longer speak but still think. The system isolates neural signals associated with speech synthesis, translating those signals into words. Here, I will analyze their discovery and discuss how it could impact the future of neuroprosthetic development.
Three crucial regions of the brain develop speech: the motor cortex, Wernicke’s area, and Broca’s area. Wernicke’s and Broca’s areas oversee speech comprehension and construction. When we hear “How are you,” Wernicke’s area comprehends what that phrase means and sends a neural signal to Broca’s area, producing a response akin to “I am doing well.” The motor cortex controls the movements of the lips, tongue, and vocal cords to produce sound in spoken words, receiving instructions from Broca’s area.
Those who have lost the ability to speak have damaged neural pathways between these regions. Most typically, the motor cortex is damaged and unable to produce the physical movement required to convey words.
In a study for Nature, Dr. Francis Willett and colleagues from Stanford University describe their highly accurate device, allowing users to generate speech in real time using thought alone. Connecting electrodes from a brain-machine interface to a brain region encompassing Broca’s and Wernicke’s area could translate the neural signals to functional text on a screen or spoken word by an assistive computer.
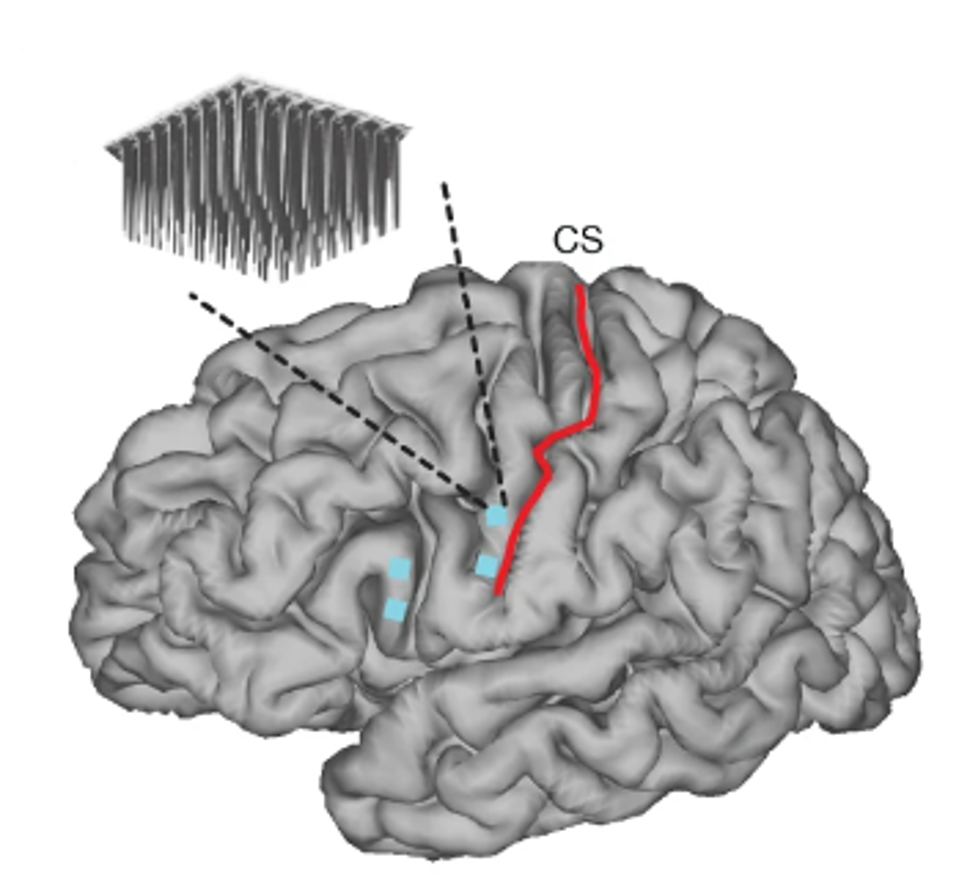
FIGURE 1: Microelectrode array locations (cyan squares) are shown on top of MRI-derived brain anatomy (CS, central sulcus).
The study focused on an individual who lost their speaking ability because of bulbar-onset amyotrophic lateral sclerosis, but is likely applicable to many. As neural signals are highly personalized, the first step was to teach the brain-machine interface the orofacial movements associated with specific neural signals, including jaw, lip, tongue, and larynx movement.
The next step was to create a training history for the system to reference when prompted to create words or phrases. The subject spent several days attempting to speak 10,850 sentences, with the neuroprosthetic monitoring neural firings and associated attempted speech movements. Each sentence was noted to ensure that the sentences used in further testing would not be replicated.
The final results were remarkably consistent and accurate even many months after implantation. The researchers tested a small pool of 50 words previously unused during learning sessions. On average, the system accurately conveyed words thought by the subject 90.9% of the time. With a much larger pool of 125,000 words, the accuracy remained high at 76.2%. Meanwhile, speech decoding averaged 62 words per minute, not far off the natural speech average of 160 words per minute.
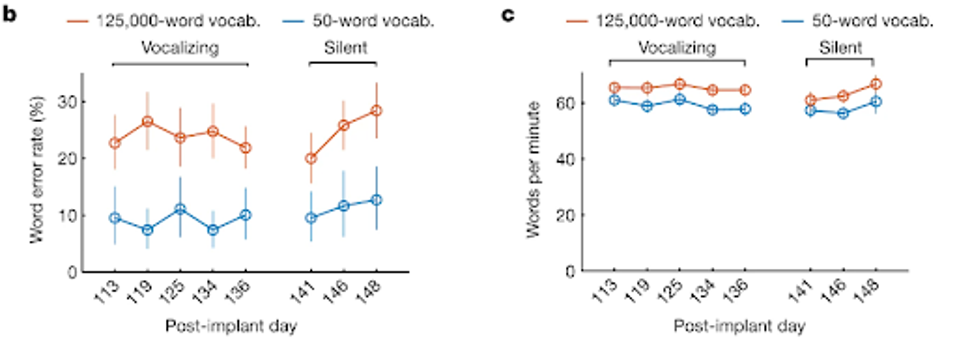
FIGURE 2: Open circles denote word error rates for two speaking modes (vocalized versus silent) and vocabulary size (50 versus 125,000 words). Word error rates were aggregated across 80 trials per day for the 125,000-word vocabulary and 50 trials per day for the 50-word vocabulary. Vertical lines indicate 95% CIs. c, Same as in b, but for speaking rate (words per minute).
This speech decoder proves that brain-machine interfaces that translate words at fast rates with massive vocabulary pools are not only possible but also currently feasible. While error in the 20-percent range is not ideal for accurate speech, that accuracy could likely be tuned over time to create a more precise system.
Of course, we must note the likely high cost of such a system and the lengthy user training and adaptation required for system optimization. This will not be available for lower or even middle-income individuals for some time, but we highly anticipate the day these technologies are easily accessible.
If widely available, such a speech decoder could serve the 5-10% of Americans with significant speech impediments, vastly improving their quality of life and laying the groundwork for full communication between those who have lost their voice and those around them. One could even see a path to autotranslation between languages, but that is a much more distant thought.
Read Dr. Haseltine's latest piece with
![]()
